
Hoy en día prácticamente todas las aplicaciones usan un diccionario de palabras, que funciona en tiempo real, marcando o subrayando en rojo las palabras que están mal escritas. Muchos procesadores de texto añaden esta capacidad para hacer más valioso su software y ayudar al usuario a escribir con mayor corrección.
Hay que decir que los idiomas son muchas veces son más complicados para corregir que simplemente hacer una búsqueda en un diccionario. Hay giros idiomáticos y anglicismos que muchas veces no se encuentran en los diccionarios, amén de que hay palabras que tienen que ver con el contexto en el que se escriben.
Pongamos un ejemplo: la palabra «solo», que se escribe sin acento si es de soledad. Si es adverbio, entonces se le pone la tilde en la primera sílaba. Así, «estoy solo» está bien escrito, pero «estoy sólo» no lo está. Y sí, sé que la Real Academia de la Lengua Española estaba quitando estos acentos diacríticos. Sin embargo, mientras no se decida cómo quedará la cosa, yo seguiré con la regla antigua.
Los elementos de una buena corrección ortográfica
En 1988 hice la maestría en Inteligencia Artificial. Mi proyecto era un corrector ortográfico inteligente. Después de analizar a detalle la problemática, llegué a la conclusión que, para tener un corrector razonablemente bueno, se requería lo siguiente:
- Ser capaz de usar reglas ortográficas: Hay más de doscientas reglas en el español. Por ejemplo, «En una palabra, después de una n va una v, después de una m va una b«. Así, «enbiar» está mal escrito y «homvre» también está mal. Si usamos las reglas, podemos olvidarnos en algunos casos de consultar las palabras en el diccionario.
- Ser capaz de usar un diccionario con miles de palabras: mientras más palabras se tengan en un diccionario, la corrección puede ser mejor.
- Ser capaz de usar diccionarios personalizados: muchas palabras no están en los diccionarios, por ejemplo, aquellas que usan términos científicos o un lenguaje especializado.
- Ser capaz de usar otras tecnologías para buscar errores, como patrones equivocados de letras: En muchas ocasiones los usuarios cambian la letras de orden y esto hace que la palabra esté mal escrita. Si podemos detectar esto, la corrección puede hacerse sin necesidad de un diccionario.
- Ser capaz de usar un diccionario de verbos ya conjugados: Curiosamente, los diccionarios normalmente traen los verbos en infinitivo pero no vienen conjugados. La conjugación es un proceso mecánico y por ende, bien podría añadirse a las capacidades del corrector. Cada verbo tiene, en general unas 50 conjugaciones y hay unos 10 mil verbos. Esto haría posible tener un diccionario -sólo de verbos (¿notaron la tilde?)- de 500 mil palabras.
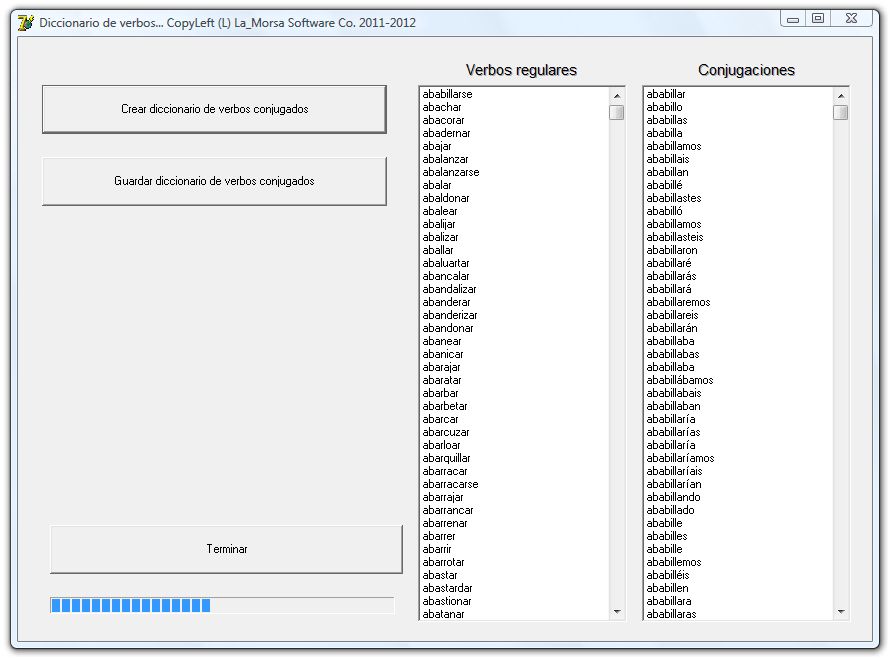
Tres tipos de corrección: interactiva, por lotes y rápida
Normalmente los procesadores de palabras corrigen mientras el usuario está escribiendo un texto. Esto es relativamente ágil para el usuario pues puede detectar errores de inmediato. Sin embargo, hay otros escenarios.
Supongamos que nos mandan un texto de muchas cuartillas. Pues bien, sería recomendable ejecutar el corrector ortográfico de manera tal que se haga automáticamente mientras hago otra cosa. Y que, cuando termine, guarde un reporte con las correcciones que hay que hacer en un archivo que pueda consultar.
Una tercera opción es hacer una «corrección rápida», usando para ello una lista de palabras más frecuentemente usadas en el español. Estas pueden encontrarse aquí.
Ahora sí, el reto lúdico
Con esto dicho, va el reto: hágase un editor de textos (puede ser del tipo bloc de notas, es decir, sin necesidad de tipos y tamaños diferentes de letras), que corrija un texto usando estas posibilidades, mientras más, mejor. Es decir, mientras más características puedan usarse (de las descritas), será un mejor candidato a ganar el premio del reto lúdico.
Más de uno preguntará: ¿Y de dónde saco el diccionario de palabras a usar? Buscando en el oráculo de Internet, encontré este sitio, que Giusseppe Domínguez tecleó las 91 mil palabras del diccionario de la RAE y las puso en un archivo de texto, el cual puede descargarse de este enlace. El autor de semejante esfuerzo nos da algunas estadísticas sobre las palabras:
Palabras en a.txt = 11135
Palabras en b.txt = 3861
Palabras en c.txt = 12697
Palabras en d.txt = 5880
Palabras en e.txt = 7332
Palabras en f.txt = 2966
Palabras en g.txt = 3000
Palabras en h.txt = 2215
Palabras en i.txt = 3308
Palabras en j.txt = 982
Palabras en k.txt = 117
Palabras en l.txt = 2531
Palabras en m.txt = 5598
Palabras en n.txt = 1351
Palabras en ñ.txt = 82
Palabras en o.txt = 1468
Palabras en p.txt = 7951
Palabras en q.txt = 521
Palabras en r.txt = 4603
Palabras en s.txt = 4713
Palabras en t.txt = 4980
Palabras en u.txt = 500
Palabras en v.txt = 2031
Palabras en w.txt = 28
Palabras en x.txt = 48
Palabras en y.txt = 267
Palabras en z.txt = 774
Palabras en total = 90939
Con esto todo está en la mesa. ¡A programar!
El ganador (si es de la Ciudad de México), se hará acreedor a una taza con el logotipo de la Morsa. Si es de otro país o de provincia, le mandaremos un USB de al menos 16 GB.

Cabe señalar que este concurso busca simplemente alentar el trabajo de la programación y mostrar que puede ser lúdica. Es un concurso de buena fe. Si hay, por ejemplo, dos o más respuestas satisfactorias, ganará quien la haya mandado primero.
El ganador cede su código fuente a la comunidad. Los que estén interesados deberán mandar sus programas a [email protected]. Quien resulte ganador deberá entregar el código fuente para compartirlo con la comunidad.
Digamos que la idea es promover la creación de software y además, hacer que ésta sea de código abierto. Si el autor decide no poner su código accesible, perderá su premio.
